

Secure by design
Trusted by




Why teams start with AI Router
Multi modality
Multi provider
Routing logic
bring your own keys
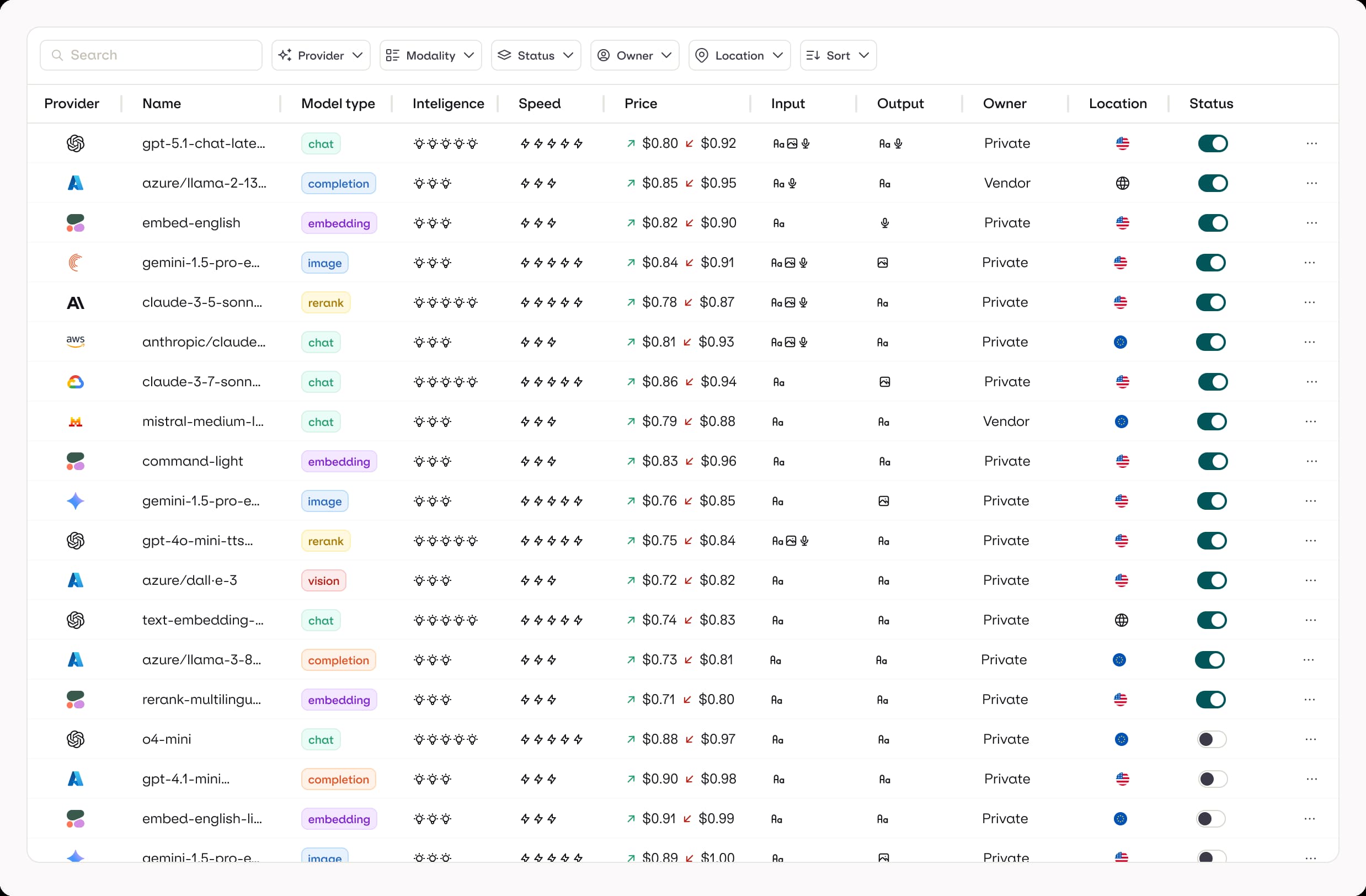
Auto retry
Fallback logic
Reliability
100% uptime
Budget control
Dashboard
Analytics
identity tracking
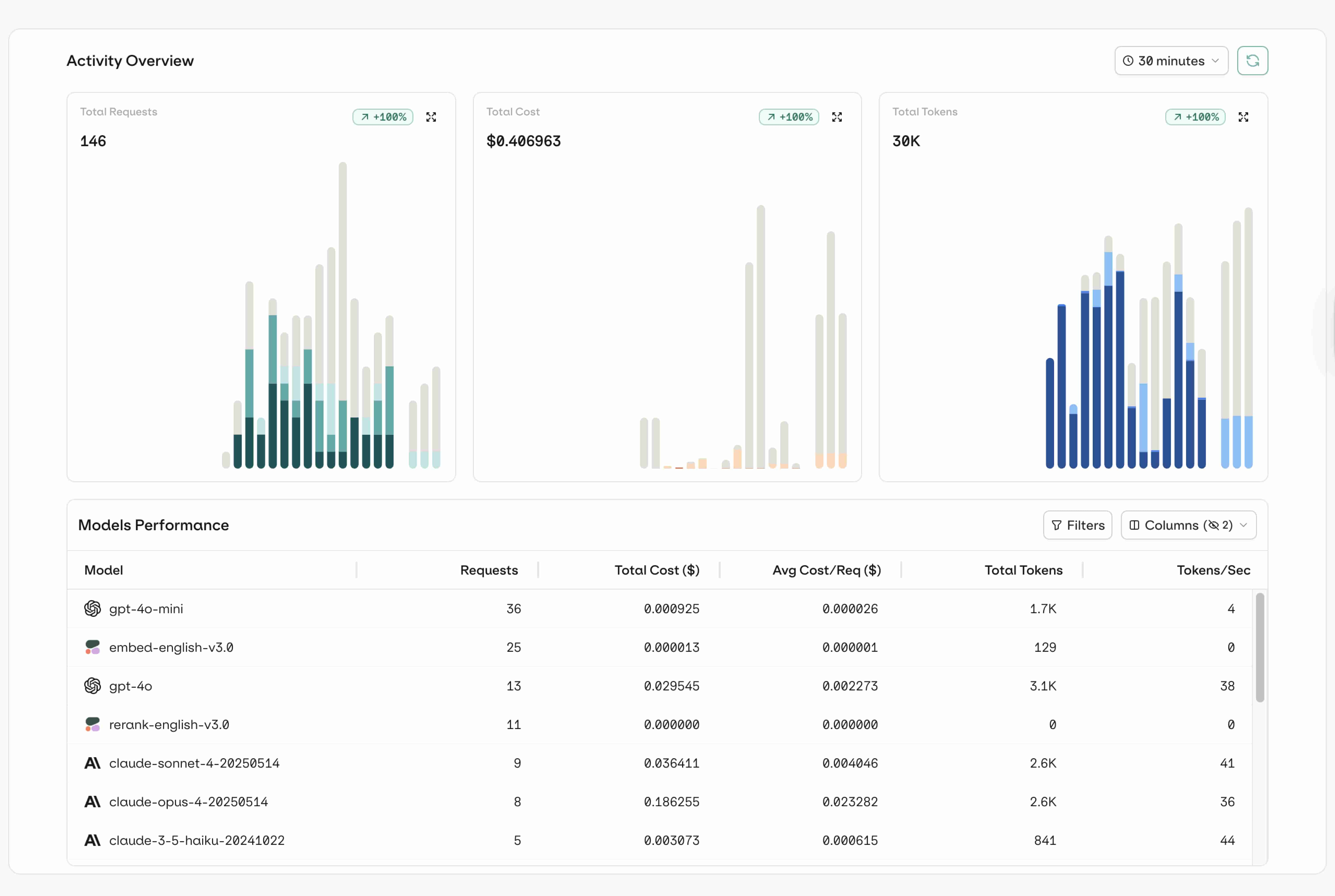
observability
tracing
Span
Threads
Debugging

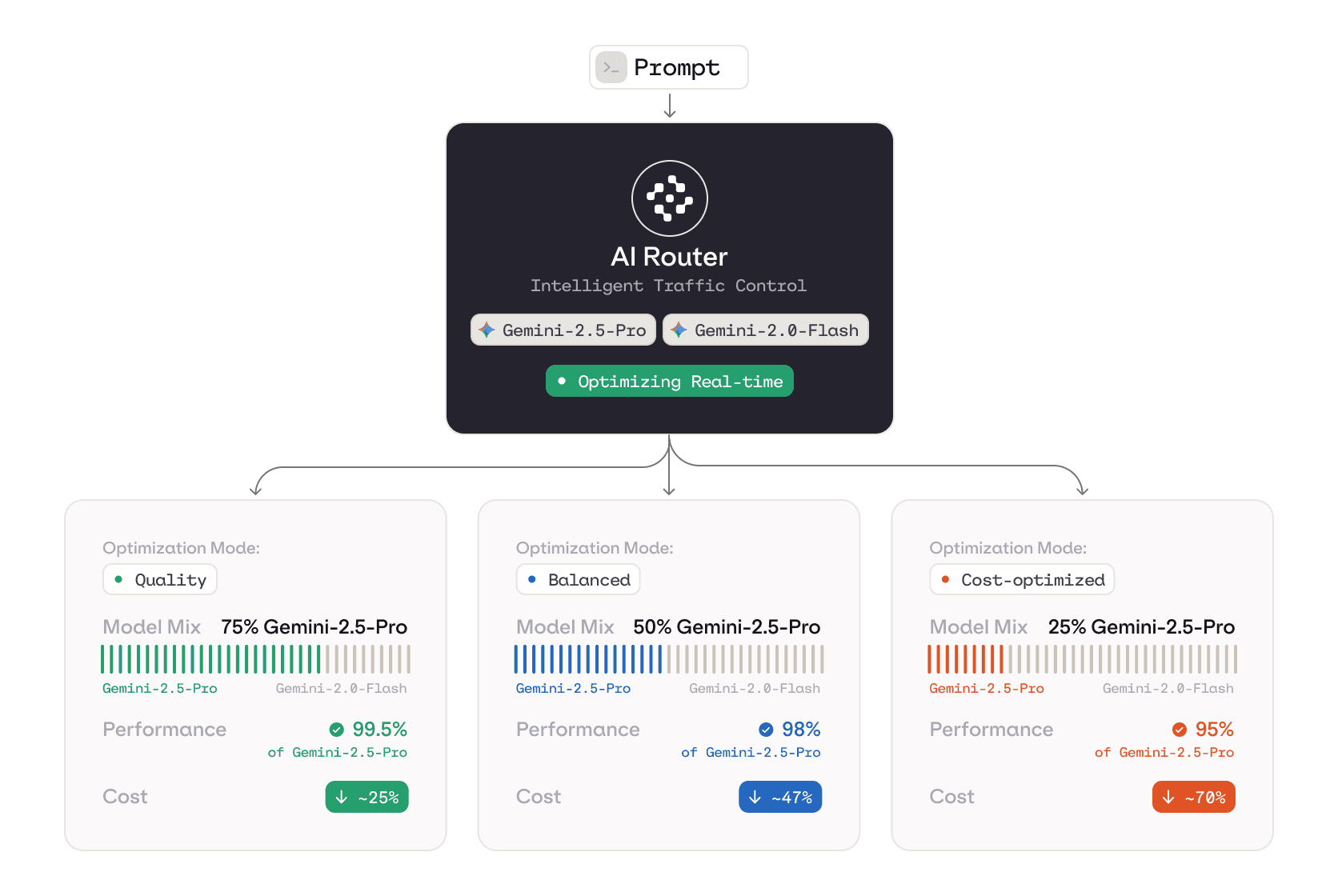
Intelligent LLM Routing
Cut LLM costs by 50% from day one
Smart router
Immediate savings without compromising quality
Orq.ai’s smart routing dynamically selects the right model for every request so simple tasks don’t burn frontier-model budgets. Instead of sending everything to your most expensive LLM “just to be safe,” the router analyzes each prompt and routes it to the most cost-effective model that still meets quality requirements.
Real time decisions
Cost Optimized
How it works
1. Sign up
Create your Orq.ai account and get instant access to the AI Router.
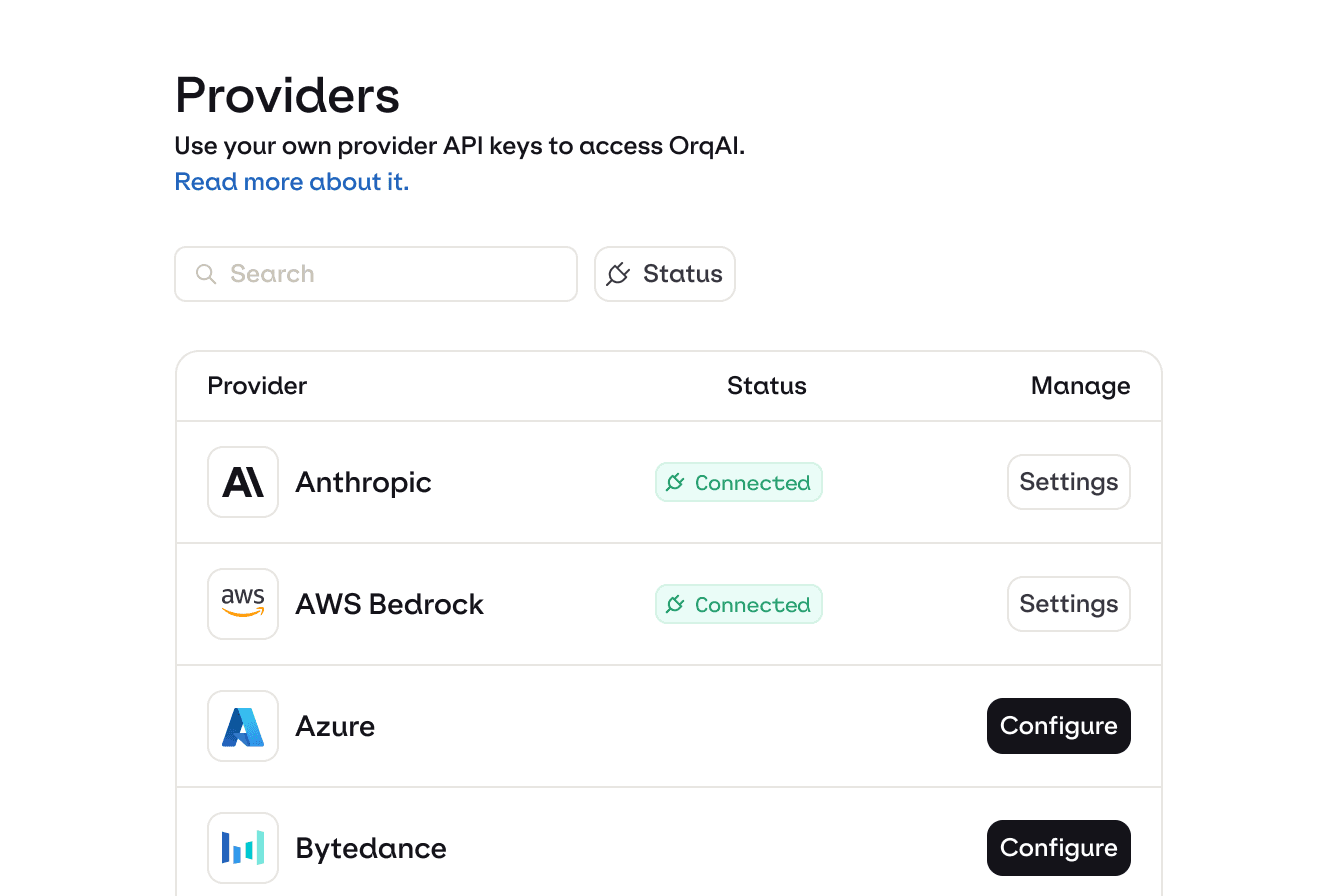
2. Enable your models
Connect and configure the models and providers you want to route across.
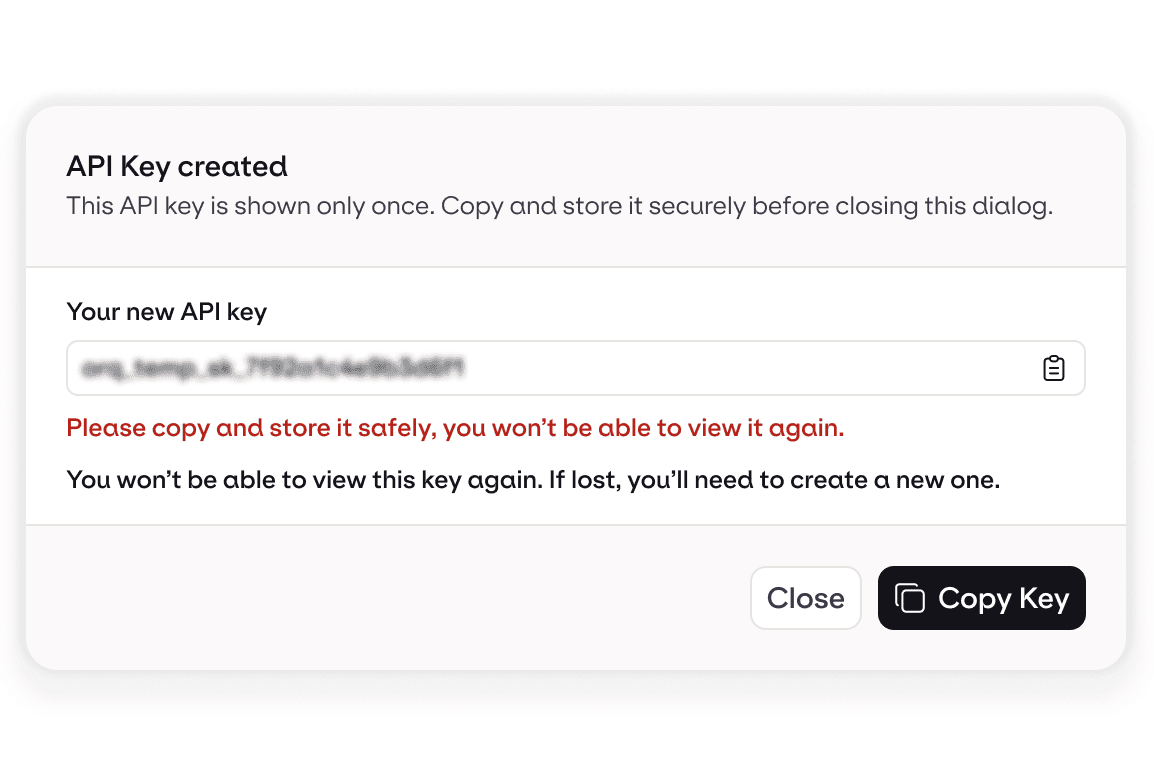
3. Get your API key
Start sending AI traffic through a single, production-ready endpoint.
Featured Models
Who it’s for
Product teams
Ship AI features to production while keeping cost, performance, and reliability in check at scale.
Platform teams
Standardize LLM access, enforce guardrails, and give teams one approved AI entry point.

Benjamin Kleppe
GenAI Lead at bunq
We built our own LLM routing infrastructure, but maintaining it became increasingly expensive and time-consuming, while still leaving gaps in observability and performance. We chose to work with Orq.ai to replace that internal setup with a production-ready AI Router that meets our governance, scalability, and cost-monitoring requirements.
